Как заставить DLP-систему работать. Предотвращение утечек данных — DLP DLP
-системы: что это такое
Если быть достаточно последовательным в определениях, то можно сказать, что информационная безопасность началась именно с появления DLP-систем. До этого все продукты, которые занимались "информационной безопасностью", на самом деле защищали не информацию, а инфраструктуру - места хранения, передачи и обработки данных. Компьютер, приложение или канал, в которых находится, обрабатывается или передается конфиденциальная информация, защищаются этими продуктами точно так же, как и инфраструктура, в которой обращается совершенно безобидная информация. То есть именно с появлением DLP-продуктов информационные системы научились наконец-то отличать конфиденциальную информацию от неконфиденциальной. Возможно, с встраиванием DLP-технологий в информационную инфраструктуру компании смогут сильно сэкономить на защите информации - например, использовать шифрование только в тех случаях, когда хранится или передается конфиденциальная информация, и не шифровать информацию в других случаях.
Однако это дело будущего, а в настоящем данные технологии используются в основном для защиты информации от утечек. Технологии категоризации информации составляют ядро DLP-систем. Каждый производитель считает свои методы детектирования конфиденциальной информации уникальными, защищает их патентами и придумывает для них специальные торговые марки. Ведь остальные, отличные от этих технологий, элементы архитектуры (перехватчики протоколов, парсеры форматов, управление инцидентами и хранилища данных) у большинства производителей идентичны, а у крупных компаний даже интегрированы с другими продуктами безопасности информационной инфраструктуры. В основном для категоризации данных в продуктах по защите корпоративной информации от утечек используются две основных группы технологий - лингвистический (морфологический, семантический) анализ и статистические методы (Digital Fingerprints, Document DNA, антиплагиат). Каждая технология имеет свои сильные и слабые стороны, которые определяют область их применения.
Лингвистический анализ
Использование стоп-слов ("секретно", "конфиденциально" и тому подобных) для блокировки исходящих электронных сообщений в почтовых серверах можно считать прародителем современных DLPсистем. Конечно, от злоумышленников это не защищает - удалить стоп-слово, чаще всего вынесенное в отдельный гриф документа, не составляет труда, при этом смысл текста нисколько не изменится.
Толчок в разработке лингвистических технологий был сделан в начале этого века создателями email-фильтров. Прежде всего, для защиты электронной почты от спама. Это сейчас в антиспамовских технологиях преобладают репутационные методы, а в начале века шла настоящая лингвистическая война между снарядом и броней - спамерами и антиспамерами. Помните простейшие методы для обмана фильтров, базирующихся на стоп-словах? Замена букв на похожие буквы из других кодировок или цифры, транслит, случайным образом расставленные пробелы, подчеркивания или переходы строк в тексте. Антиспамеры довольно быстро научились бороться с такими хитростями, но тогда появился графический спам и прочие хитрые разновидности нежелательной корреспонденции.
Однако использовать антиспамерские технологии в DLP-продуктах без серьезной доработки невозможно. Ведь для борьбы со спамом достаточно делить информационный поток на две категории: спам и не спам. Метод Байеса, который используется при детектировании спама, дает только бинарный результат: "да" или "нет". Для защиты корпоративных данных от утечек этого недостаточно - нельзя просто делить информацию на конфиденциальную и неконфиденциальную. Нужно уметь классифицировать информацию по функциональной принадлежности (финансовая, производственная, технологическая, коммерческая, маркетинговая), а внутри классов - категоризировать ее по уровню доступа (для свободного распространения, для ограниченного доступа, для служебного использования, секретная, совершенно секретная и так далее).
Большинство современных систем лингвистического анализа используют не только контекстный анализ (то есть в каком контексте, в сочетании с какими другими словами используется конкретный термин), но и семантический анализ текста. Эти технологии работают тем эффективнее, чем больше анализируемый фрагмент. На большом фрагменте текста точнее проводится анализ, с большей вероятностью определяется категория и класс документа. При анализе же коротких сообщений (SMS, интернет-пейджеры) ничего лучшего, чем стоп-слова, до сих пор не придумано. Автор столкнулся с такой задачей осенью 2008 года, когда с рабочих мест многих банков через мессенджеры пошли в Сеть тысячи сообщений типа "нас сокращают", "отберут лицензию", "отток вкладчиков", которые нужно было немедленно заблокировать у своих клиентов.
Достоинства технологии
Достоинства лингвистических технологий в том, что они работают напрямую с содержанием документов, то есть им не важно, где и как был создан документ, какой на нем гриф и как называется файл - документы защищаются немедленно. Это важно, например, при обработке черновиков конфиденциальных документов или для защиты входящей документации. Если документы, созданные и использующиеся внутри компании, еще как-то можно специфическим образом именовать, грифовать или метить, то входящие документы могут иметь не принятые в организации грифы и метки. Черновики (если они, конечно, не создаются в системе защищенного документооборота) тоже могут уже содержать конфиденциальную информацию, но еще не содержать необходимых грифов и меток.
Еще одно достоинство лингвистических технологий - их обучаемость. Если ты хоть раз в жизни нажимал в почтовом клиенте кнопку "Не спам", то уже представляешь клиентскую часть системы обучения лингвистического движка. Замечу, что тебе совершенно не нужно быть дипломированным лингвистом и знать, что именно изменится в базе категорий - достаточно указать системе ложное срабатывание, все остальное она сделает сама.
Третьим достоинством лингвистических технологий является их масштабируемость. Скорость обработки информации пропорциональна ее количеству и абсолютно не зависит от количества категорий. До недавнего времени построение иерархической базы категорий (исторически ее называют БКФ - база контентной фильтрации, но это название уже не отражает настоящего смысла) выглядело неким шаманством профессиональных лингвистов, поэтому настройку БКФ можно было смело отнести к недостаткам. Но с выходом в 2010 сразу нескольких продуктов-"автолингвистов" построение первичной базы категорий стало предельно простым - системе указываются места, где хранятся документы определенной категории, и она сама определяет лингвистические признаки этой категории, а при ложных срабатываниях - самостоятельно обучается. Так что теперь к достоинствам лингвистических технологий добавилась простота настройки.
И еще одно достоинство лингвистических технологий, которое хочется отметить в статье - возможность детектировать в информационных потоках категории, не связанные с документами, находящимися внутри компании. Инструмент для контроля содержимого информационных потоков может определять такие категории, как противоправная деятельность (пиратство, распространение запрещенных товаров), использование инфраструктуры компании в собственных целях, нанесение вреда имиджу компании (например, распространение порочащих слухов) и так далее.
Недостатки технологий
Основным недостатком лингвистических технологий является их зависимость от языка. Невозможно использовать лингвистический движок, разработанный для одного языка, в целях анализа другого. Это было особенно заметно при выходе на российский рынок американских производителей - они были не готовы столкнуться с российским словообразованием и наличием шести кодировок. Недостаточно было перевести на русский язык категории и ключевые слова - в английском языке словообразование довольно простое, а падежи выносятся в предлоги, то есть при изменении падежа меняется предлог, а не само слово. Большинство существительных в английском языке становятся глаголами без изменений слова. И так далее. В русском все не так - один корень может породить десятки слов в разных частях речи.
В Германии американских производителей лингвистических технологий встретила другая проблема - так называемые "компаунды", составные слова. В немецком языке принято присоединять определения к главному слову, в результате чего получаются слова, иногда состоящие из десятка корней. В английском языке такого нет, там слово - последовательность букв между двумя пробелами, соответственно английский лингвистический движок оказался неспособен обработать незнакомые длинные слова.
Справедливости ради следует сказать, что сейчас эти проблемы во многом американскими производителями решены. Пришлось довольно сильно переделать (а иногда и писать заново) языковой движок, но большие рынки России и Германии наверняка того стоят. Также сложно обрабатывать лингвистическими технологиями мультиязычные тексты. Однако с двумя языками большинство движков все-таки справляются, обычно это национальный язык + английский - для большинства бизнес-задач этого вполне достаточно. Хотя автору встречались конфиденциальные тексты, содержащие, например, одновременно казахский, русский и английский, но это скорее исключение, чем правило.
Еще одним недостатком лингвистических технологий для контроля всего спектра корпоративной конфиденциальной информации является то, что не вся конфиденциальная информация находится в виде связных текстов. Хотя в базах данных информация и хранится в текстовом виде, и нет никаких проблем извлечь текст из СУБД, полученная информация чаще всего содержит имена собственные - ФИО, адреса, названия компаний, а также цифровую информацию - номера счетов, кредитных карт, их баланс и прочее. Обработка подобных данных с помощью лингвистики много пользы не принесет. То же самое можно сказать о форматах CAD/CAM, то есть чертежах, в которых зачастую содержится интеллектуальная собственность, программных кодах и медийных (видео/аудио) форматах - какие-то тексты из них можно извлечь, но их обработка также неэффективна. Еще года три назад это касалось и отсканированных текстов, но лидирующие производители DLP-систем оперативно добавили оптическое распознавание и справились с этой проблемой.
Но самым большим и наиболее часто критикуемым недостатком лингвистических технологий является все-таки вероятностный подход к категоризации. Если ты когда-нибудь читал письмо с категорией "Probably SPAM", то поймешь, о чем я. Если такое творится со спамом, где всего две категории (спам/не спам), можно себе представить, что будет, когда в систему загрузят несколько десятков категорий и классов конфиденциальности. Хотя обучением системы можно достигнуть 92-95% точности, для большинства пользователей это означает, что каждое десятое или двадцатое перемещение информации будет ошибочно причислено не к тому классу со всеми вытекающими для бизнеса последствиями (утечка или прерывание легитимного процесса).
Обычно не принято относить к недостаткам сложность разработки технологии, но не упомянуть о ней нельзя. Разработка серьезного лингвистического движка с категоризацией текстов более чем по двум категориям - наукоемкий и довольно сложный технологически процесс. Прикладная лингвистика - быстро развивающаяся наука, получившая сильный толчок в развитии с распространением интернет-поиска, но сегодня на рынке присутствуют единицы работоспособных движков категоризации: для русского языка их всего два, а для некоторых языков их просто еще не разработали. Поэтому на DLP-рынке существует лишь пара компаний, которые способны в полной мере категоризировать информацию "на лету". Можно предположить, что когда рынок DLP увеличится до многомиллиардных размеров, на него с легкостью выйдет Google. С собственным лингвистическим движком, оттестированным на триллионах поисковых запросов по тысячам категорий, ему не составит труда сразу отхватить серьезный кусок этого рынка.
Статистические методы
Задача компьютерного поиска значимых цитат (почему именно "значимых" - немного позже) заинтересовала лингвистов еще в 70-х годах прошлого века, если не раньше. Текст разбивался на куски определенного размера, с каждого из которых снимался хеш. Если некоторая последовательность хешей встречалась в двух текстах одновременно, то с большой вероятностью тексты в этих областях совпадали.
Побочным продуктом исследований в этой области является, например, "альтернативная хронология" Анатолия Фоменко, уважаемого ученого, который занимался "корреляциями текстов" и однажды сравнил русские летописи разных исторических периодов. Удивившись, насколько совпадают летописи разных веков (более чем на 60%), в конце 70-х он выдвинул теорию, что наша хронология на несколько веков короче. Поэтому, когда какая-то выходящая на рынок DLP-компания предлагает "революционную технологию поиска цитат", можно с большой вероятностью утверждать, что ничего, кроме новой торговой марки, компания не создала.
Статистические технологии относятся к текстам не как к связной последовательности слов, а как к произвольной последовательности символов, поэтому одинаково хорошо работают с текстами на любых языках. Поскольку любой цифровой объект - хоть картинка, хоть программа - тоже последовательность символов, то те же методы могут применяться для анализа не только текстовой информации, но и любых цифровых объектов. И если совпадают хеши в двух аудиофайлах - наверняка в одном из них содержится цитата из другого, поэтому статистические методы являются эффективными средствами защиты от утечки аудио и видео, активно применяющиеся в музыкальных студиях и кинокомпаниях.
Самое время вернуться к понятию "значимая цитата". Ключевой характеристикой сложного хеша, снимаемого с защищаемого объекта (который в разных продуктах называется то Digital Fingerprint, то Document DNA), является шаг, с которым снимается хеш. Как можно понять из описания, такой "отпечаток" является уникальной характеристикой объекта и при этом имеет свой размер. Это важно, поскольку если снять отпечатки с миллионов документов (а это объем хранилища среднего банка), то для хранения всех отпечатков понадобится достаточное количество дискового пространства. От шага хеша зависит размер такого отпечатка - чем меньше шаг, тем больше отпечаток. Если снимать хеш с шагом в один символ, то размер отпечатка превысит размер самого образца. Если для уменьшения "веса" отпечатка увеличить шаг (например, 10 000 символов), то вместе с этим увеличивается вероятность того, что документ, содержащий цитату из образца длиной в 9 900 символов, будет конфиденциальным, но при этом проскочит незаметно.
С другой стороны, если для увеличения точности детекта брать очень мелкий шаг, несколько символов, то можно увеличить количество ложных срабатываний до неприемлемой величины. В терминах текста это означает, что не стоит снимать хеш с каждой буквы - все слова состоят из букв, и система будет принимать наличие букв в тексте за содержание цитаты из текста-образца. Обычно производители сами рекомендуют некоторый оптимальный шаг снятия хешей, чтобы размер цитаты был достаточный и при этом вес самого отпечатка был небольшой - от 3% (текст) до 15% (сжатое видео). В некоторых продуктах производители позволяют менять размер значимости цитаты, то есть увеличивать или уменьшать шаг хеша.
Достоинства технологии
Как можно понять из описания, для детектирования цитаты нужен объект-образец. И статистические методы могут с хорошей точностью (до 100%) сказать, есть в проверяемом файле значимая цитата из образца или нет. То есть система не берет на себя ответственность за категоризацию документов - такая работа полностью лежит на совести того, кто категоризировал файлы перед снятием отпечатков. Это сильно облегчает защиту информации в случае, если на предприятии в некотором месте (местах) хранятся нечасто изменяющиеся и уже категоризированные файлы. Тогда достаточно с каждого из этих файлов снять отпечаток, и система будет, в соответствии с настройками, блокировать пересылку или копирование файлов, содержащих значимые цитаты из образцов.
Независимость статистических методов от языка текста и нетекстовой информации - тоже неоспоримое преимущество. Они хороши при защите статических цифровых объектов любого типа - картинок, аудио/видео, баз данных. Про защиту динамических объектов я расскажу в разделе "недостатки".
Недостатки технологии
Как и в случае с лингвистикой, недостатки технологии - обратная сторона достоинств. Простота обучения системы (указал системе файл, и он уже защищен) перекладывает на пользователя ответственность за обучение системы. Если вдруг конфиденциальный файл оказался не в том месте либо не был проиндексирован по халатности или злому умыслу, то система его защищать не будет. Соответственно, компании, заботящиеся о защите конфиденциальной информации от утечки, должны предусмотреть процедуру контроля того, как индексируются DLP-системой конфиденциальные файлы.
Еще один недостаток - физический размер отпечатка. Автор неоднократно видел впечатляющие пилотные проекты на отпечатках, когда DLP-система со 100% вероятностью блокирует пересылку документов, содержащих значимые цитаты из трехсот документов-образцов. Однако через год эксплуатации системы в боевом режиме отпечаток каждого исходящего письма сравнивается уже не с тремя сотнями, а с миллионами отпечатков-образцов, что существенно замедляет работу почтовой системы, вызывая задержки в десятки минут.
Как я и обещал выше, опишу свой опыт по защите динамических объектов с помощью статистических методов. Время снятия отпечатка напрямую зависит от размера файла и его формата. Для текстового документа типа этой статьи это занимает доли секунды, для полуторачасового MP4-фильма - десятки секунд. Для редкоизменяемых файлов это не критично, но если объект меняется каждую минуту или даже секунду, то возникает проблема: после каждого изменения объекта с него нужно снять новый отпечаток... Код, над которым работает программист, еще не самая большая сложность, гораздо хуже с базами данных, используемыми в биллинге, АБС или call-центрах. Если время снятия отпечатка больше, чем время неизменности объекта, то задача решения не имеет. Это не такой уж и экзотический случай - например, отпечаток базы данных, хранящей номера телефонов клиентов федерального сотового оператора, снимается несколько дней, а меняется ежесекундно. Поэтому, когда DLP-вендор утверждает, что его продукт может защитить вашу базу данных, мысленно добавляйте слово "квазистатическую".
Единство и борьба противоположностей
Как видно из предыдущего раздела статьи, сила одной технологии проявляется там, где слаба другая. Лингвистике не нужны образцы, она категоризирует данные на лету и может защищать информацию, с которой случайно или умышленно не был снят отпечаток. Отпечаток дает лучшую точность и поэтому предпочтительнее для использования в автоматическом режиме. Лингвистика отлично работает с текстами, отпечатки - с другими форматами хранения информации.
Поэтому большинство компаний-лидеров используют в своих разработках обе технологии, при этом одна из них является основной, а другая - дополнительной. Это связано с тем, что изначально продукты компании использовали только одну технологию, в которой компания продвинулась дальше, а затем, по требованию рынка, была подключена вторая. Так, например, ранее InfoWatch использовал только лицензированную лингвистическую технологию Morph-OLogic, а Websense - технологию PreciseID, относящуюся к категории Digital Fingerprint, но сейчас компании используют оба метода. В идеале использовать две эти технологии нужно не параллельно, а последовательно. Например, отпечатки лучше справятся с определением типа документа - договор это или балансовая ведомость, например. Затем можно подключать уже лингвистическую базу, созданную специально для этой категории. Это сильно экономит вычислительные ресурсы.
За пределами статьи остались еще несколько типов технологий, используемых в DLP-продуктах. К таким относятся, например, анализатор структур, позволяющий находить в объектах формальные структуры (номера кредитных карт, паспортов, ИНН и так далее), которые невозможно детектировать ни с помощью лингвистики, ни с помощью отпечатков. Также не раскрыта тема разного типа меток - от записей в атрибутных полях файла или просто специального наименования файлов до специальных криптоконтейнеров. Последняя технология отживает свое, поскольку большинство производителей предпочитает не изобретать велосипед самостоятельно, а интегрироваться с производителями DRM-систем, такими как Oracle IRM или Microsoft RMS.
DLP-продукты - быстроразвивающаяся отрасль информационной безопасности, у некоторых производителей новые версии выходят очень часто, более одного раза в год. С нетерпением ждем появления новых технологий анализа корпоративного информационного поля для увеличения эффективности защиты конфиденциальной информации.
Даже самые модные ИТ-термины надо употреблять к месту и максимально корректно. Хотя бы для того, чтобы не вводить в заблуждение потребителей. Относить себя к производителям DLP-решений определенно вошло в моду. К примеру, на недавней выставке CeBIT-2008 надпись “DLP solution” нередко можно было лицезреть на стендах производителей не только малоизвестных в мире антивирусов и прокси-серверов, но даже брандмауэров. Иногда возникало ощущение, что за следующим углом можно будет увидеть какой-нибудь CD ejector (программа, управляющая открыванием привода CD) с гордым лозунгом корпоративного DLP-решения. И, как это ни странно, каждый из таких производителей, как правило, имел более или менее логичное объяснение такому позиционированию своего продукта (естественно, помимо желания получить “гешефт” от модного термина).
Прежде чем рассматривать рынок производителей DLP-систем и его основных игроков, следует определиться с тем, что же мы будем подразумевать под DLP-системой. Попыток дать определение этому классу информационных систем было много: ILD&P — Information Leakage Detection & Prevention (“выявление и предотвращение утечек информации”, термин был предложен IDC в 2007 г.), ILP - Information Leakage Protection (“защита от утечек информации”, Forrester, 2006 г.), ALS - Anti-Leakage Software (“антиутечное ПО”, E&Y), Content Monitoring and Filtering (CMF, Gartner), Extrusion Prevention System (по аналогии с Intrusion-prevention system).
Но в качестве общеупотребительного термина всё же утвердилось название DLP - Data Loss Prevention (или Data Leak Prevention, защита от утечек данных), предложенная в 2005 г. В качестве русского (скорее не перевода, а аналогичного термина) было принято словосочетание “системы защиты конфиденциальных данных от внутренних угроз”. При этом под внутренними угрозами понимаются злоупотребления (намеренные или случайные) со стороны сотрудников организации, имеющих легальные права доступа к соответствующим данным, своими полномочиями.
Наиболее стройные и непротиворечивые критерии принадлежности к DLP-системам были выдвинуты исследовательским агентством Forrester Research в ходе их ежегодного исследования данного рынка. Они предложили четыре критерия, в соответствии с которыми систему можно отнести к классу DLP. 1.
Многоканальность. Система должна быть способна осуществлять мониторинг нескольких возможных каналов утечки данных. В сетевом окружении это как минимум e-mail, Web и IM (instant messengers), а не только сканирование почтового трафика или активности базы данных. На рабочей станции - мониторинг файловых операций, работы с буфером обмена данными, а также контроль e-mail, Web и IM. 2.
Унифицированный менеджмент. Система должна обладать унифицированными средствами управления политикой информационной безопасности, анализом и отчетами о событиях по всем каналам мониторинга. 3.
Активная защита. Система должна не только обнаруживать факты нарушения политики безопасности, но и при необходимости принуждать к ее соблюдению. К примеру, блокировать подозрительные сообщения. 4.
Исходя из этих критериев, в 2008 г. для обзора и оценки агентство Forrester отобрало список из 12 производителей программного обеспечения (ниже они перечислены в алфавитном порядке, при этом в скобках указано название компании, поглощенной данным вендором в целях выхода на рынок DLP-cистем):
- Code Green;
- InfoWatch;
- McAfee (Onigma);
- Orchestria;
- Reconnex;
- RSA/EMC (Tablus);
- Symantec (Vontu);
- Trend Micro (Provilla);
- Verdasys;
- Vericept;
- Websense (PortAuthority);
- Workshare.
На сегодняшний день из вышеупомянутых 12 вендоров на российском рынке в той или иной степени представлены только InfoWatch и Websense. Остальные либо вообще не работают в России, либо только анонсировали свои намерения о начале продаж DLP-решений (Trend Micro).
Рассматривая функциональность DLP-систем, аналитики (Forrester, Gartner, IDC) вводят категоризацию объектов защиты - типов информационных объектов подлежащих мониторингу. Подобная категоризация позволяет в первом приближении оценить область применения той или иной системы. Выделяют три категории объектов мониторинга.
1. Data-in-motion (данные в движении) - сообщения электронной почты, интернет-пейджеров, сетей peer-to-peer, передача файлов, Web-трафик, а также другие типы сообщений, которые можно передавать по каналам связи. 2. Data-at-rest (хранящиеся данные) - информация на рабочих станциях, лаптопах, файловых серверах, в специализированных хранилищах, USB-устройствах и других типах устройств хранения данных.
3. Data-in-use (данные в использовании) - информация, обрабатываемая в данный момент.
В настоящий момент на нашем рынке представлено около двух десятков отечественных и зарубежных продуктов, обладающих некоторыми свойствами DLP-cистем. Краткие сведения о них в духе приведенной выше классификации, перечислены в табл. 1 и 2. Также в табл. 1 внесен такой параметр, как “централизованное хранилище данных и аудит”, подразумевающий возможность системы сохранять данные в едином депозитарии (для всех каналов мониторинга) для их дальнейшего анализа и аудита. Этот функционал приобретает в последнее время особенную значимость не только в силу требований различных законодательных актов, но и в силу популярности у заказчиков (по опыту реализованных проектов). Все сведения, содержащиеся в этих таблицах, взяты из открытых источников и маркетинговых материалов соответствующих компаний.
Исходя из приведенных в таблицах 1 и 2 данных можно сделать вывод, что на сегодня в России представлены только три DLP-системы (от компаний InfoWatch, Perimetrix и WebSence). К ним также можно отнести недавно анонсированный интегрированный продукт от “Инфосистемы Джет” (СКВТ+СМАП), так как он будет покрывать несколько каналов и иметь унифицированный менеджмент политик безопасности.
Говорить о долях рынка этих продуктов в России довольно сложно, поскольку большинство упомянутых производителей не раскрывают объемов продаж, количество клиентов и защищенных рабочих станций, ограничиваясь только маркетинговой информацией. Точно можно сказать лишь о том, что основными поставщиками на данный момент являются:
- системы “Дозор”, присутствующие на рынке с 2001 г.;
- продукты InfoWatch, продающиеся с 2004 г.;
- WebSense CPS (начал продаваться в России и во всем мире в 2007 г.);
- Perimetrix (молодая компания, первая версия продуктов которой анонсирована на ее сайте на конец 2008 г.).
В заключение хотелось бы добавить, что принадлежность или нет к классу DLP-систем, не делает продукты хуже или лучше - это просто вопрос классификации и ничего более.
| Компания | Продукт | Возможности продукта | |||
|---|---|---|---|---|---|
| Защита “данных в движении” (data-in-motion) | Защита “данных в использовании” (data-in-use) | Защита “данных в хранении” (data-at-rest) | Централизованное хранилище и аудит | ||
| InfoWatch | IW Traffic Monitor | Да | Да | Нет | Да |
| IW CryptoStorage | Нет | Нет | Да | Нет | |
| Perimetrix | SafeSpace | Да | Да | Да | Да |
| Инфосистемы Джет | Дозор Джет (СКВТ) | Да | Нет | Нет | Да |
| Дозор Джет (СМАП) | Да | Нет | Нет | Да | |
| Смарт Лайн Инк | DeviceLock | Нет | Да | Нет | Да |
| SecurIT | Zlock | Нет | Да | Нет | Нет |
| SecrecyKeeper | Нет | Да | Нет | Нет | |
| SpectorSoft | Spector 360 | Да | Нет | Нет | Нет |
| Lumension Security | Sanctuary Device Control | Нет | Да | Нет | Нет |
| WebSense | Websense Content Protection | Да | Да | Да | Нет |
| Информзащита | Security Studio | Нет | Да | Да | Нет |
| Праймтек | Insider | Нет | Да | Нет | Нет |
| АтомПарк Софтваре | StaffCop | Нет | Да | Нет | Нет |
| СофтИнформ | SearchInform Server | Да | Да | Нет | Нет |
| Компания | Продукт | Критерий принадлежности к DLP системам | |||
|---|---|---|---|---|---|
| Многоканальность | Унифицированный менеджмент | Активная защита | Учет как содержания, так и контекста | ||
| InfoWatch | IW Traffic Monitor | Да | Да | Да | Да |
| Perimetrix | SafeSpace | Да | Да | Да | Да |
| “Инфосистемы Джет” | “Дозор Джет” (СКВТ) | Нет | Нет | Да | Да |
| “Дозор Джет” (СМАП) | Нет | Нет | Да | Да | |
| “Смарт Лайн Инк” | DeviceLock | Нет | Нет | Нет | Нет |
| SecurIT | Zlock | Нет | Нет | Нет | Нет |
| Smart Protection Labs Software | SecrecyKeeper | Да | Да | Да | Нет |
| SpectorSoft | Spector 360 | Да | Да | Да | Нет |
| Lumension Security | Sanctuary Device Control | Нет | Нет | Нет | Нет |
| WebSense | Websense Content Protection | Да | Да | Да | Да |
| “Информзащита” | Security Studio | Да | Да | Да | Нет |
| “Праймтек” | Insider | Да | Да | Да | Нет |
| “АтомПарк Софтваре” | StaffCop | Да | Да | Да | Нет |
| “СофтИнформ” | SearchInform Server | Да | Да | Нет | Нет |
| “Инфооборона” | “Инфопериметр” | Да | Да | Нет | Нет |
28.01.2014 Сергей Кораблев
Выбор любого продукта корпоративного уровня является для технических специалистов и сотрудников, принимающих решения, задачей нетривиальной. Выбор системы предотвращения утечек данных Data Leak Protection (DLP) – еще сложнее. Отсутствие единой понятийной системы, регулярных независимых сравнительных исследований и сложность самих продуктов вынуждают потребителей заказывать у производителей пилотные проекты и самостоятельно проводить многочисленные тестирования, определяя круг собственных потребностей и соотнося их с возможностями проверяемых систем
Подобный поход, безусловно, правильный. Взвешенное, а в некоторых случаях даже выстраданное решение упрощает дальнейшее внедрение и позволяет избежать разочарования при эксплуатации конкретного продукта. Однако процесс принятия решений в данном случае может затягиваться если не на годы, то на многие месяцы. Кроме того, постоянное расширение рынка, появление новых решений и производителей еще более усложняют задачу не только выбора продукта для внедрения, но и создание предварительного шорт-листа подходящих DLP-систем. В таких условиях актуальные обзоры DLP-систем имеют несомненную практическую ценность для технических специалистов. Стоит ли включать конкретное решение в список для тестирования или оно будет слишком сложным для внедрения в небольшой организации? Может ли решение быть масштабировано на компанию из 10 тыс. сотрудников? Сможет ли DLP-система контролировать важные для бизнеса CAD-файлы? Открытое сравнение не заменит тщательного тестирования, но поможет ответить на базовые вопросы, возникающие на начальном этапе работ по выбору DLP.
Участники
В качестве участников были выбраны наиболее популярные (по версии аналитического центра Anti-Malware.ru на середину 2013 года) на российском рынке информационной безопасности DLP-системы компаний InfoWatch, McAfee, Symantec, Websense, Zecurion и «Инфосистем Джет».
Для анализа использовались коммерчески доступные на момент подготовки обзора версии DLP-систем, а также документация и открытые обзоры продуктов.
Критерии сравнения DLP-систем выбирались, исходя из потребностей компаний различного размера и разных отраслей. Под основной задачей DLP-систем подразумевается предотвращение утечек конфиденциальной информации по различным каналам.
Примеры продуктов этих компаний представлены на рисунках 1–6.
.jpg) |
| Рисунок 3. Продукт компании Symantec |
.jpg) |
| Рисунок 4. Продукт компании InfoWatch |
.jpg) |
| Рисунок 5. Продукт компании Websense |
.jpg) |
| Рисунок 6. Продукт компании McAfee |
Режимы работы
Два основных режима работы DLP-систем – активный и пассивный. Активный – обычно основной режим работы, при котором происходит блокировка действий, нарушающих политики безопасности, например отправка конфиденциальной информации на внешний почтовый ящик. Пассивный режим чаще всего используется на этапе настройки системы для проверки и корректировки настроек, когда высока доля ложных срабатываний. В этом случае нарушения политик фиксируются, но ограничения на перемещение информации не налагаются (таблица 1).
.jpg) |
В данном аспекте все рассматриваемые системы оказались равнозначны. Каждая из DLP умеет работать как в активном, так и в пассивном режимах, что дает заказчику определенную свободу. Не все компании готовы начать эксплуатацию DLP сразу в режиме блокировки – это чревато нарушением бизнес-процессов, недовольством со стороны сотрудников контролируемых отделов и претензиями (в том числе обоснованными) со стороны руководства.
Технологии
Технологии детектирования позволяют классифицировать информацию, которая передается по электронным каналам и выявлять конфиденциальные сведения. На сегодня существует несколько базовых технологий и их разновидностей, сходных по сути, но различных по реализации. Каждая из технологий имеет как преимущества, так и недостатки. Кроме того, разные типы технологий подходят для анализа информации различных классов. Поэтому производители DLP-решений стараются интегрировать в свои продукты максимальное количество технологий (см. таблицу 2).
В целом, продукты предоставляют большое количество технологий, позволяющих при должной настройке обеспечить высокий процент распознавания конфиденциальной информации. DLP McAfee, Symantec и Websense довольно слабо адаптированы для российского рынка и не могут предложить пользователям поддержку «языковых» технологий – морфологии, анализа транслита и замаскированного текста.
Контролируемые каналы
Каждый канал передачи данных – это потенциальный канал утечек. Даже один открытый канал может свести на нет все усилия службы информационной безопасности, контролирующей информационные потоки. Именно поэтому так важно блокировать неиспользуемые сотрудниками для работы каналы, а оставшиеся контролировать с помощью систем предотвращения утечек.
Несмотря на то, что лучшие современные DLP-системы способны контролировать большое количество сетевых каналов (см. таблицу 3), ненужные каналы целесообразно блокировать. К примеру, если сотрудник работает на компьютере только с внутренней базой данных, имеет смысл вообще отключить ему доступ в Интернет.
Аналогичные выводы справедливы и для локальных каналов утечки. Правда, в этом случае бывает сложнее заблокировать отдельные каналы, поскольку порты часто используются и для подключения периферии, устройств ввода-вывода и т. д.
Особую роль для предотвращения утечек через локальные порты, мобильные накопители и устройства играет шифрование. Средства шифрования достаточно просты в эксплуатации, их использование может быть прозрачным для пользователя. Но в то же время шифрование позволяет исключить целый класс утечек, связанных с несанкционированным доступом к информации и утерей мобильных накопителей.
Ситуация с контролем локальных агентов в целом хуже, чем с сетевыми каналами (см. таблицу 4). Успешно контролируются всеми продуктами только USB-устройства и локальные принтеры. Также, несмотря на отмеченную выше важность шифрования, такая возможность присутствует только в отдельных продуктах, а функция принудительного шифрования на основе контентного анализа присутствует только в Zecurion DLP.
Для предотвращения утечек важно не только распознавание конфиденциальных данных в процессе передачи, но и ограничение распространения информации в корпоративной среде. Для этого в состав DLP-систем производители включают инструменты, способные выявлять и классифицировать информацию, хранящуюся на серверах и рабочих станциях в сети (см. таблицу 5). Данные, которые нарушают политики информационной безопасности, должны быть удалены или перемещены в безопасное хранилище.
Для выявления конфиденциальной информации на узлах корпоративной сети используются те же самые технологии, что и для контроля утечек по электронным каналам. Главное отличие – архитектурное. Если для предотвращения утечки анализируется сетевой трафик или файловые операции, то для обнаружения несанкционированных копий конфиденциальных данных исследуется хранимая информация – содержимое рабочих станций и серверов сети.
Из рассматриваемых DLP-систем только InfoWatch и «Дозор-Джет» игнорируют использование средств выявления мест хранения информации. Это не является критичной функцией для предотвращения утечки по электронным каналам, но существенно ограничивает возможности DLP-систем в отношении проактивного предотвращения утечек. К примеру, когда конфиденциальный документ находится в пределах корпоративной сети, это не является утечкой информации. Однако если место хранения этого документа не регламентировано, если о местонахождении этого документа не знают владельцы информации и офицеры безопасности, это может привести к утечке. Возможен несанкционированный доступ к информации или к документу не будут применены соответствующие правила безопасности.
Удобство управления
Такие характеристики как удобство использования и управления могут быть не менее важными, чем технические возможности решений. Ведь действительно сложный продукт будет трудно внедрить, проект отнимет больше времени, сил и, соответственно, финансов. Уже внедренная DLP-система требует к себе внимания со стороны технических специалистов. Без должного обслуживания, регулярного аудита и корректировки настроек качество распознавания конфиденциальной информации будет со временем сильно падать.
Интерфейс управления на родном для сотрудника службы безопасности языке – первый шаг для упрощения работы с DLP-системой. Он позволит не только облегчить понимание, за что отвечает та или иная настройка, но и значительно ускорит процесс конфигурирования большого количества параметров, которые необходимо настроить для корректной работы системы. Английский язык может быть полезен даже для русскоговорящих администраторов для однозначной трактовки специфических технических понятий (см. таблицу 6).
Большинство решений предусматривают вполне удобное управление из единой (для всех компонентов) консоли c веб-интерфейсом (см. таблицу 7). Исключение составляют российские InfoWatch (отсутствует единая консоль) и Zecurion (нет веб-интерфейса). При этом оба производителя уже анонсировали появление веб-консоли в своих будущих продуктах. Отсутствие же единой консоли у InfoWatch обусловлено различной технологической основой продуктов. Разработка собственного агентского решения была на несколько лет прекращена, а нынешний EndPoint Security является преемником продукта EgoSecure (ранее известного как cynapspro) стороннего разработчика, приобретенного компанией в 2012 году.
Еще один момент, который можно отнести к недостаткам решения InfoWatch, состоит в том, что для настройки и управления флагманским DLP-продуктом InfoWatch TrafficMonitor необходимо знание специального скриптового языка LUA, что усложняет эксплуатацию системы. Тем не менее, для большинства технических специалистов перспектива повышения собственного профессионального уровня и изучение дополнительного, пусть и не слишком ходового языка должна быть воспринята позитивно.
Разделение ролей администратора системы необходимо для минимизации рисков предотвращения появления суперпользователя с неограниченными правами и других махинаций с использованием DLP.
Журналирование и отчеты
Архив DLP – это база данных, в которой аккумулируются и хранятся события и объекты (файлы, письма, http-запросы и т. д.), фиксируемые датчиками системы в процессе ее работы. Собранная в базе информация может применяться для различных целей, в том числе для анализа действий пользователей, для сохранения копий критически важных документов, в качестве основы для расследования инцидентов ИБ. Кроме того, база всех событий чрезвычайно полезна на этапе внедрения DLP-системы, поскольку помогает проанализировать поведение компонентов DLP-системы (к примеру, выяснить, почему блокируются те или иные операции) и осуществить корректировку настроек безопасности (см. таблицу 8).
.jpg) |
В данном случае мы видим принципиальное архитектурное различие между российскими и западными DLP. Последние вообще не ведут архив. В этом случае сама DLP становится более простой для обслуживания (отсутствует необходимость вести, хранить, резервировать и изучать огромный массив данных), но никак не для эксплуатации. Ведь архив событий помогает настраивать систему. Архив помогает понять, почему произошла блокировка передачи информации, проверить, сработало ли правило корректно, внести в настройки системы необходимые исправления. Также следует заметить, что DLP-системы нуждаются не только в первичной настройке при внедрении, но и в регулярном «тюнинге» в процессе эксплуатации. Система, которая не поддерживается должным образом, не доводится техническими специалистами, будет много терять в качестве распознавания информации. В результате возрастет и количество инцидентов, и количество ложных срабатываний.
Отчетность – немаловажная часть любой деятельности. Информационная безопасность – не исключение. Отчеты в DLP-системах выполняют сразу несколько функций. Во-первых, краткие и понятные отчеты позволяют руководителям служб ИБ оперативно контролировать состояние защищенности информации, не вдаваясь в детали. Во-вторых, подробные отчеты помогают офицерам безопасности корректировать политики безопасности и настройки систем. В-третьих, наглядные отчеты всегда можно показать топ-менеджерам компании для демонстрации результатов работы DLP-системы и самих специалистов по ИБ (см. таблицу 9).
Почти все конкурирующие решения, рассмотренные в обзоре, предлагают и графические, удобные топ-менеджерам и руководителям служб ИБ, и табличные, более подходящие техническим специалистам, отчеты. Графические отчеты отсутствуют только в DLP InfoWatch, за что им и была снижена оценка.
Сертификация
Вопрос о необходимости сертификации для средств обеспечения информационной безопасности и DLP в частности является открытым, и в рамках профессиональных сообществ эксперты часто спорят на эту тему. Обобщая мнения сторон, следует признать, что сама по себе сертификация не дает серьезных конкурентных преимуществ. В то же время, существует некоторое количество заказчиков, прежде всего, госорганизаций, для которых наличие того или иного сертификата является обязательным.
Кроме того, существующий порядок сертификации плохо соотносится с циклом разработки программных продуктов. В результате потребители оказываются перед выбором: купить уже устаревшую, но сертифицированную версию продукта или актуальную, но не прошедшую сертификацию. Стандартный выход в этой ситуации – приобретение сертифицированного продукта «на полку» и использование нового продукта в реальной среде (см. таблицу 10).
Результаты сравнения
Обобщим впечатления от рассмотренных DLP-решений. В целом, все участники произвели благоприятное впечатление и могут использоваться для предотвращения утечек информации. Различия продуктов позволяют конкретизировать область их применения.
DLP-система InfoWatch может быть рекомендована организациям, для которых принципиально важно наличие сертификата ФСТЭК. Впрочем, последняя сертифицированная версия InfoWatch Traffic Monitor проходила испытания еще в конце 2010 года, а срок действия сертификата истекает в конце 2013 года. Агентские решения на базе InfoWatch EndPoint Security (известного также как EgoSecure) больше подходят предприятиям малого бизнеса и могут использоваться отдельно от Traffic Monitor. Совместное использование Traffic Monitor и EndPoint Security может вызвать проблемы с масштабированием в условиях крупных компаний.
Продукты западных производителей (McAfee, Symantec, Websense), по данным независимых аналитических агентств, значительно менее популярны, нежели российские. Причина - в низком уровне локализации. Причем дело даже не в сложности интерфейса или отсутствии документации на русском языке. Особенности технологий распознавания конфиденциальной информации, преднастроенные шаблоны и правила «заточены» под использование DLP в западных странах и нацелены на выполнение западных же нормативных требований. В результате в России качество распознавания информации оказывается заметно хуже, а выполнение требований иностранных стандартов зачастую неактуально. При этом сами по себе продукты вовсе не плохие, но специфика применения DLP-систем на российском рынке вряд ли позволит им в обозримом будущем стать более популярными, чем отечественные разработки.
Zecurion DLP отличается хорошей масштабируемостью (единственная российская DLP-система с подтвержденным внедрением на более чем 10 тыс. рабочих мест) и высокой технологической зрелостью. Однако удивляет отсутствие веб-консоли, что помогло бы упростить управление корпоративным решением, нацеленным на различные сегменты рынка. Среди сильных сторон Zecurion DLP – высокое качество распознавания конфиденциальной информации и полная линейка продуктов для предотвращения утечек, включая защиту на шлюзе, рабочих станциях и серверах, выявление мест хранения информации и инструменты для шифрования данных.
DLP-система «Дозор-Джет», один из пионеров отечественного рынка DLP, широко распространена среди российских компаний и продолжает наращивать клиентскую базу за счет обширных связей системного интегратора «Инфосистемы Джет», по совместительству и разработчика DLP. Хотя технологически DLP несколько отстает от более мощных собратьев, ее использование может быть оправдано во многих компаниях. Кроме того, в отличие от иностранных решений, «Дозор Джет» позволяет вести архив всех событий и файлов.
Утечка коммерчески значимой информации может привести к существенным убыткам компании – и финансовым, и репутационным. Настройка компонентов DLP позволяет отслеживать внутреннюю переписку, почтовые сообщения, обмен данными, работу с облачными хранилищами, запуск приложений на рабочем столе, подключение внешних устройств, отчеты, смс-сообщения, телефонные переговоры. Все подозрительные операции контролируются и создается база отчетности по отслеженным прецедентам. Для этого DLP-системы имеют встроенные механизмы определения системы конфиденциальной информации, для чего анализируются специальные маркеры документов и само их содержание (по ключевым словам, фразам, предложениям). Возможен ряд дополнительных настроек по контролю персонала (правомерности действий внутри компании, использования рабочих ресурсов, вплоть до распечаток на принтерах).
Если в приоритете полноценный контроль над передачей данных, то первоначальная настройка DLP будет заключаться в выявлении и определении возможных утечек информации, контроля конечных устройств и допуска пользователей к ресурсам компании. Если в приоритете статистика по перемещению важной корпоративной информации внутри организации, то для ее отслеживания вычисляются каналы и способы передачи данных. DLP-системы настраиваются индивидуально под каждое предприятие, исходя из предполагаемых моделей угроз, категорий нарушений, определения возможных каналов утечек информации.
DLP занимают большую нишу на рынке в сфере экономической безопасности. Исходя из исследований Аналитического центра Anti-Malware.ru , заметен рост потребности компаний в DLP-системах, увеличение продаж и расширение линейки продуктов. Актуальна настройка предотвращения передачи не желаемой информации не только изнутри наружу, но и снаружи внутрь информационной сети предприятия. Более того, учитывая распространенную виртуализацию в корпоративных информационных системах и повсеместное использования мобильных устройств, через которые ведется бизнес контроль мобильных сотрудников — одна из самых приоритетных задач.
Важно учитывать интеграцию выбранных DLP-систем с корпоративной IT-сетью, теми приложениями, которые использует компания. Для успешного предотвращения утечки данных и оперативных действий по пресечению злоупотребления корпоративной информацией, необходимо наладить стабильную работу DLP, настроить функционал в соответствии с задачами, установить работу с внутрикорпоративными электронными ящиками, USB-накопителями, мессенджерами, облачными хранилищами, мобильными устройствами, а в случае работы в большой корпорации — и интеграцию с SIEM системой в рамках SOC.
Доверьте внедрение системы DLP специалистам. Системный интегратор «Radius» осуществит установку и настройку DLP в соответствии со стандартами и нормами информационной безопасности, а также особенностями компании-клиента.
С егодня рынок DLP-систем является одним из самых быстрорастущих среди всех средств обеспечения информационной безопасности. Впрочем, отечественная ИБ-сфера пока не совсем успевает за мировыми тенденциями, в связи с чем у рынка DLP-систем в нашей стране есть свои особенности.
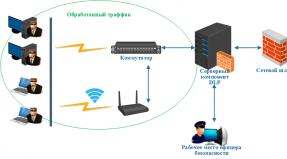
Что такое DLP и как они работают?
Прежде чем говорить о рынке DLP-систем, необходимо определиться с тем, что, собственно говоря, подразумевается, когда речь идёт о подобных решениях. Под DLP-системами принято понимать программные продукты, защищающие организации от утечек конфиденциальной информации. Сама аббревиатура DLP расшифровывается как Data Leak Prevention, то есть, предотвращение утечек данных.
Подобного рода системы создают защищенный цифровой «периметр» вокруг организации, анализируя всю исходящую, а в ряде случаев и входящую информацию. Контролируемой информацией должен быть не только интернет-трафик, но и ряд других информационных потоков: документы, которые выносятся за пределы защищаемого контура безопасности на внешних носителях, распечатываемые на принтере, отправляемые на мобильные носители через Bluetooth и т.д.
Поскольку DLP-система должна препятствовать утечкам конфиденциальной информации, то она в обязательном порядке имеет встроенные механизмы определения степени конфиденциальности документа, обнаруженного в перехваченном трафике. Как правило, наиболее распространены два способа: путём анализа специальных маркеров документа и путём анализа содержимого документа. В настоящее время более распространен второй вариант, поскольку он устойчив перед модификациями, вносимыми в документ перед его отправкой, а также позволяет легко расширять число конфиденциальных документов, с которыми может работать система.
«Побочные» задачи DLP
Помимо своей основной задачи, связанной с предотвращением утечек информации, DLP-системы также хорошо подходят для решения ряда других задач, связанных с контролем действий персонала.
Наиболее часто DLP-системы применяются для решения следующих неосновных для себя задач:
- контроль использования рабочего времени и рабочих ресурсов сотрудниками;
- мониторинг общения сотрудников с целью выявления «подковерной» борьбы, которая может навредить организации;
- контроль правомерности действий сотрудников (предотвращение печати поддельных документов и пр.);
- выявление сотрудников, рассылающих резюме, для оперативного поиска специалистов на освободившуюся должность.
За счет того, что многие организации полагают ряд этих задач (особенно контроль использования рабочего времени) более приоритетными, чем защита от утечек информации, возник целый ряд программ, предназначенных именно для этого, однако способных в ряде случаев работать и как средство защиты организации от утечек. От полноценных DLP-систем такие программы отличает отсутствие развитых средств анализа перехваченных данных, который должен производиться специалистом по информационной безопасности вручную, что удобно только для совсем небольших организаций (до десяти контролируемых сотрудников).